Benchmarks
Below are AI inferencing benchmarks for Jetson Orin Nano Super and Jetson AGX Orin .
Jetson Orin Nano Super

| Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
|---|---|---|---|
| Llama 3.1 8B | 14 | 19.14 | 1.37 |
| Llama 3.2 3B | 27.7 | 43.07 | 1.55 |
| Qwen2.5 7B | 14.2 | 21.75 | 1.53 |
| Gemma 2 2B | 21.5 | 34.97 | 1.63 |
| Gemma 2 9B | 7.2 | 9.21 | 1.28 |
| Phi 3.5 3B | 24.7 | 38.1 | 1.54 |
| SmolLM2 | 41 | 64.5 | 1.57 |
For running these benchmarks, this script will launch a series of containers that download/build/run the models with MLC and INT4 quantization.
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
bash jetson-containers/packages/llm/mlc/benchmarks.sh
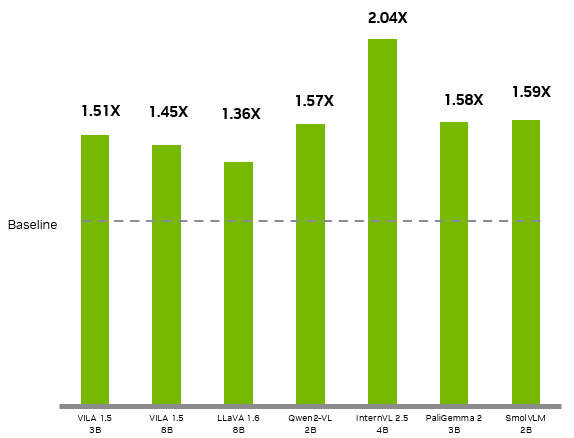
| Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
|---|---|---|---|
| VILA 1.5 3B | 0.7 | 1.06 | 1.51 |
| VILA 1.5 8B | 0.574 | 0.83 | 1.45 |
| LLAVA 1.6 7B | 0.412 | 0.57 | 1.38 |
| Qwen2 VL 2B | 2.8 | 4.4 | 1.57 |
| InternVL2.5 4B | 2.5 | 5.1 | 2.04 |
| PaliGemma2 3B | 13.7 | 21.6 | 1.58 |
| SmolVLM 2B | 8.1 | 12.9 | 1.59 |
![]()
| Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
|---|---|---|---|
| clip-vit-base-patch32 | 196 | 314 | 1.60 |
| clip-vit-base-patch16 | 95 | 161 | 1.69 |
| DINOv2-base-patch14 | 75 | 126 | 1.68 |
| SAM2 base | 4.42 | 6.34 | 1.43 |
| Grounding DINO | 4.11 | 6.23 | 1.52 |
| vit-base-patch16-224 | 98 | 158 | 1.61 |
| vit-base-patch32-224 | 171 | 273 | 1.60 |
Jetson AGX Orin

For running LLM benchmarks, see the
MLC
container documentation.

Small language models are generally defined as having fewer than 7B parameters
(Llama-7B shown for reference)
For more data and info about running these models, see the
SLM
tutorial and
MLC
container documentation.

This measures the end-to-end pipeline performance for continuous streaming like with
Live Llava
.
For more data and info about running these models, see the
NanoVLM
tutorial.


For running Riva benchmarks, see ASR Performance and TTS Performance .

For running vector database benchmarks, see the
NanoDB
container documentation.