Tutorial - Live LLaVA
Recommended
Follow the NanoVLM tutorial first to familiarize yourself with vision/language models, and see Agent Studio for in interactive pipeline editor built from live VLMs.
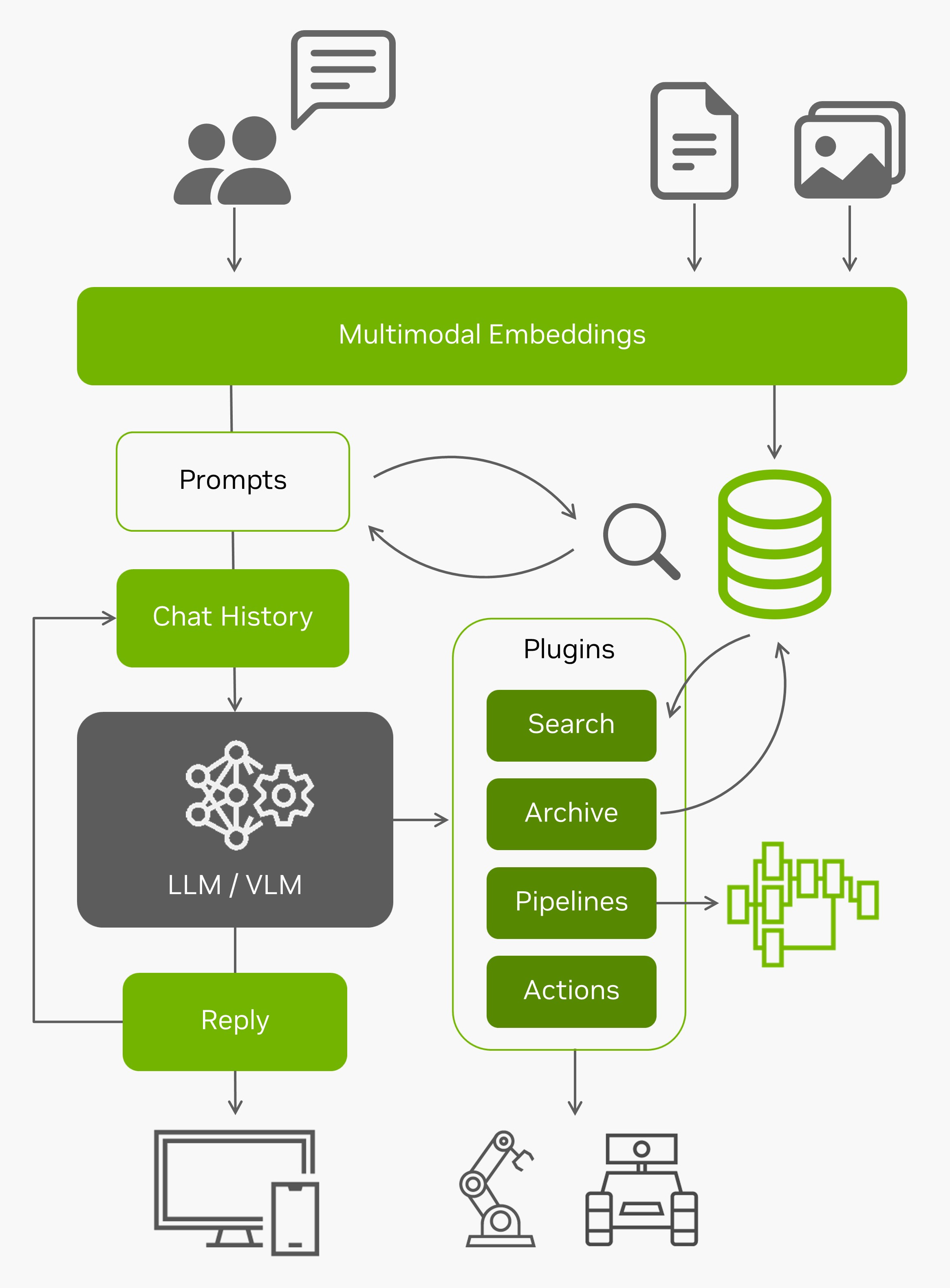
This multimodal agent runs a vision-language model on a live camera feed or video stream, repeatedly applying the same prompts to it:

It uses models like
LLaVA
or
VILA
and has been quantized with 4-bit precision. This runs an optimized multimodal pipeline from the
NanoLLM
library, including running the CLIP/SigLIP vision encoder in TensorRT, event filters and alerts, and multimodal RAG (see the
NanoVLM
page for benchmarks)
Running the Live Llava Demo
What you need
-
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB) Jetson Orin Nano (8GB) ⚠️
-
Running one of the following versions of JetPack :
JetPack 6 (L4T r36.x)
-
NVMe SSD highly recommended for storage speed and space
-
22GBfornano_llmcontainer image -
Space for models (
>10GB)
-
-
Supported vision/language models:
-
liuhaotian/llava-v1.5-7b,liuhaotian/llava-v1.5-13b,liuhaotian/llava-v1.6-vicuna-7b,liuhaotian/llava-v1.6-vicuna-13b -
Efficient-Large-Model/VILA-2.7b,Efficient-Large-Model/VILA-7b,Efficient-Large-Model/VILA-13b -
Efficient-Large-Model/VILA1.5-3b,Efficient-Large-Model/Llama-3-VILA1.5-8B,Efficient-Large-Model/VILA1.5-13b -
VILA-2.7b,VILA1.5-3b,VILA-7b,Llava-7b, andObsidian-3Bcan run on Orin Nano 8GB
-
The
VideoQuery
agent applies prompts to the incoming video feed with the VLM. Navigate your browser to
https://<IP_ADDRESS>:8050
after launching it with your camera (Chrome is recommended with
chrome://flags#enable-webrtc-hide-local-ips-with-mdns
disabled)
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.agents.video_query --api=mlc \
--model Efficient-Large-Model/VILA1.5-3b \
--max-context-len 256 \
--max-new-tokens 32 \
--video-input /dev/video0 \
--video-output webrtc://@:8554/output
This uses
jetson_utils
for video I/O, and for options related to protocols and file formats, see
Camera Streaming and Multimedia
. In the example above, it captures a V4L2 USB webcam connected to the Jetson (under the device
/dev/video0
) and outputs a WebRTC stream.
Processing a Video File or Stream
The example above was running on a live camera, but you can also read and write a
video file or network stream
by substituting the path or URL to the
--video-input
and
--video-output
command-line arguments like this:
jetson-containers run \
-v /path/to/your/videos:/mount
$(autotag nano_llm) \
python3 -m nano_llm.agents.video_query --api=mlc \
--model Efficient-Large-Model/VILA1.5-3b \
--max-context-len 256 \
--max-new-tokens 32 \
--video-input /mount/my_video.mp4 \
--video-output /mount/output.mp4 \
--prompt "What does the weather look like?"
This example processes and pre-recorded video (in MP4, MKV, AVI, FLV formats with H.264/H.265 encoding), but it also can input/output live network streams like RTP , RTSP , and WebRTC using Jetson's hardware-accelerated video codecs.
NanoDB Integration
If you launch the
VideoQuery
agent with the
--nanodb
flag along with a path to your NanoDB database, it will perform reverse-image search on the incoming feed against the database by re-using the CLIP embeddings generated by the VLM.
To enable this mode, first follow the NanoDB tutorial to download, index, and test the database. Then launch VideoQuery like this:
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.agents.video_query --api=mlc \
--model Efficient-Large-Model/VILA1.5-3b \
--max-context-len 256 \
--max-new-tokens 32 \
--video-input /dev/video0 \
--video-output webrtc://@:8554/output \
--nanodb /data/nanodb/coco/2017
You can also tag incoming images and add them to the database using the web UI, for one-shot recognition tasks:
Video VILA
The VILA-1.5 family of models can understand multiple images per query, enabling video search/summarization, action & behavior analysis, change detection, and other temporal-based vision functions. The
vision/video.py
example keeps a rolling history of frames:
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.video \
--model Efficient-Large-Model/VILA1.5-3b \
--max-images 8 \
--max-new-tokens 48 \
--video-input /data/my_video.mp4 \
--video-output /data/my_output.mp4 \
--prompt 'What changes occurred in the video?'
")
Python Code
For a simplified code example of doing live VLM streaming from Python, see here in the NanoLLM docs.
You can use this to implement customized prompting techniques and integrate with other vision pipelines. This code applies the same set of prompts to the latest image from the video feed. See here for the version that does multi-image queries on video sequences.