OpenVLA - Vision/Language Action Models for Embodied Robotics
Fine Tuning and Deployment Guide
The tutorials's goal is to provide optimized quantization and inference for deploying VLA models, along with reference fine-tuning workflows for adapting models for new robots, tasks, and environments. Rigorous performance and accuracy validation is applied in a self-contained sim environment with scenario generation and domain randomization ( MimicGen ). Future phases will include sim2real with Isaac Lab and ROS2 integration, study of related models like CrossFormer and optimizations to the neural architecture for realtime performance.
✅ Quantization and inference optimizations for VLA models
✅ Accuracy validation of the original OpenVLA-7B weights
✅ Reference fine-tuning workflow with synthetic data generation
✅ On-device training with LoRA's on Jetson AGX Orin and full fine-tuning on A100/H100 instances
✅ 85% accuracy on an example block-stacking task with domain randomization
✅ Sample datasets and test models for reproducing results
Thank you to OpenVLA, Open X-Embodiment, MimicGen, Robosuite and many others with related work for sharing their promising research, models, and tools for advancing physical AI and robotics.
VLA Architecture
OpenVLA is a vision/language action model for embodied robotics and behavioral learning built on LLM/VLMs (this base model is a Prismatic VLM using Llama-7B, DINOv2, and SigLIP). Instead of image captioning or visual question/answering, VLA models generate action tokens from camera images and natural language instructions that are used for controlling the robot. Action tokens are discrete token ID's reserved from the text tokenizer's vocabulary that map to continuous values, normalized against the range of motion of each robot. These real-valued tokens are more efficient and accurate than the model outputting numerical data as text in JSON or Pydantic formats, where each digit, decimal point, separator, and whitespace takes an additional token to generate. Other hybrid vision/language models like Florence-2 have adopted similar approaches for continuous-domain prediction using Transformers.
Each action token generated by the model represents a degree-of-freedom of the output coordinate space (i.e. xyz, rotation pose), or a component of the robot that can be controlled (like the gripper). OpenVLA-7B was trained on the
Open X-Embodiment
dataset for manipulation, with a 7-DoF action space consisting of
(delta xyz, delta roll/pitch/yaw, gripper)
. The position and rotation are relative changes to the end-effector (EEF) pose, with an external inverse kinematics (IK) solution like
cuMotion
solving joint constraints specific to each robotic arm. The gripper dimension is an absolute control between 0 (open) and 1 (closed) that does not recieve further scaling/normalization.
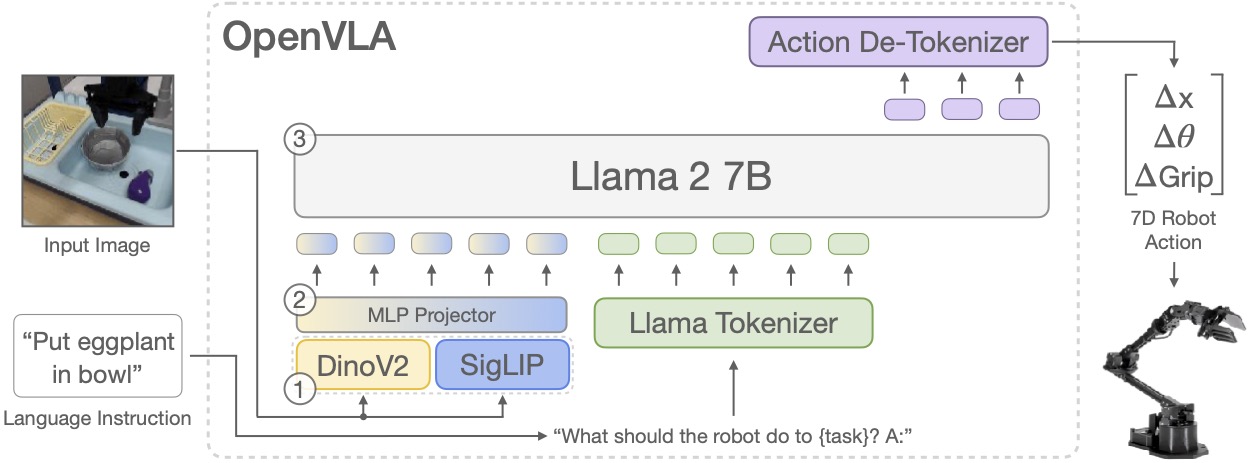
OpenVLA reserves 256 of the least-frequently used tokens out of the Llama-7B vocabulary for action values, which gives it 8-bit resolution over the controls. It has an input image resolution of 224x224 to stacked DINOv2/SigLIP vision encoders that are projected to ~275 input tokens (plus the text prompt), and outputs 7 tokens mapped to
(Δpos, Δrotation, gripper)
coordinates.
Quantization
What you need
-
One of the following Jetson devices:
Jetson AGX Orin (64GB) Jetson AGX Orin (32GB) Jetson Orin NX (16GB)
-
Running one of the following versions of JetPack :
JetPack 6 (L4T r36.x)
-
NVMe SSD highly recommended for storage speed and space
-
22GBfornano_llmcontainer image -
Space for models and datasets (
>15GB)
-
-
Clone and setup
jetson-containers:git clone https://github.com/dusty-nv/jetson-containers bash jetson-containers/install.sh
Support for OpenVLA has been added to NanoLLM on top of its streaming VLM pipeline with INT4/FP8 quantization using MLC and vision encoders in FP16 with TensorRT. First we'll test the model on BridgeData V2 , one of the top weighted datasets from the Open X-Embodiment collection. The model was trained on this data and is used to confirm that the quantization and inference are working correctly during deployment. This is what the dataset looks like, courtesy of their website :
The following command starts the container, downloads the dataset and model (if needed), quantizes it on the first run, and measures the accuracy of the action values against the groundtruth from the dataset using normalized mean-squared error ( NRMSE ) to unbias the varying ranges each dimension of the action space can have. We extracted a 100-episode subset of the original Bridge data here on HuggingFace Hub, so you don't need to download the entire ~400GB dataset just for these tests.
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.vla --api mlc \
--model openvla/openvla-7b \
--quantization q4f16_ft \
--dataset dusty-nv/bridge_orig_ep100 \
--dataset-type rlds \
--max-episodes 10 \
--save-stats /data/benchmarks/openvla_bridge_int4.json
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.vla --api mlc \
--model openvla/openvla-7b \
--quantization q8f16_ft \
--dataset dusty-nv/bridge_orig_ep100 \
--dataset-type rlds \
--max-episodes 10 \
--save-stats /data/benchmarks/openvla_bridge_fp8.json
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.vla --api hf \
--model openvla/openvla-7b \
--dataset dusty-nv/bridge_orig_ep100 \
--dataset-type rlds \
--max-episodes 10 \
--save-stats /data/benchmarks/openvla_bridge_fp16.json
| Quantization | Accuracy | Latency | FPS |
|---|---|---|---|
| FP16 | 95.3% | 840 ms | 1.19 |
| FP8 | 95.2% | 471 ms | 2.12 |
| INT4 | 90.1% | 336 ms | 2.97 |
These results were run on Jetson AGX Orin 64GB with JetPack 6, and we will see later with our fine-tuned model the INT4 accuracy match FP8/FP16.
Each frame, the 7D action vector predicted by the model is printed along with the groundtruth, along with the accuracy, latency, and framerate for that frame. The numbers printed after
~
are the averages of those so far, with the last value reported being the mean over the entire dataset processed.
# INT4
step 355 [-0.02692 0.00776 -0.00299 0.08160 0.07292 0.04791 0.99608] accuracy 0.8466 ~0.9017 time=336.2 ms fps=2.96 ~2.97
gt 355 [-0.02387 0.00760 -0.00318 0.15965 0.07707 0.03281 1.00000]
# FP8
step 355 [-0.02392 0.00767 -0.00310 0.08160 0.07692 0.03217 0.99608] accuracy 0.9982 ~0.9523 time=469.7 ms fps=2.13 ~2.12
gt 355 [-0.02387 0.00760 -0.00318 0.15965 0.07707 0.03281 1.00000]
# FP16
step 355 [-0.02392 0.00767 -0.00310 0.08160 0.07692 0.03217 0.99608] accuracy 0.9982 ~0.9531 time=842.3 ms fps=1.19 ~1.18
gt 355 [-0.02387 0.00760 -0.00318 0.15965 0.07707 0.03281 1.00000]
The per-frame metrics and averages can be saved with the
--save-stats
argument, and in the interests of time you can cap the amount of episodes processed with
--max-episodes
. As mentioned above, the Bridge dataset used was included in the training dataset, and further below we run this again on data we generated not from the training dataset with significant variation. This tool can also load other datasets in RLDS/TFDS format from Open X-Embodiment, and HDF5 from Robomimic/MimicGen. You can also create your own agents and scripts using the exposed APIs from the coding examples below.
Inference API
The code is simple for running VLA inference on camera streams using the NanoLLM library in the container:
from nano_llm import NanoLLM
from nano_llm.plugins import VideoSource
# load vision/language action model
model = NanoLLM.from_pretrained(model, quantization='q4f16_ft')
camera = VideoSource(video_source, cuda_stream=0)
assert(model.vla) # make sure this is a VLA
while True:
# returns a cudaImage, np.ndarray, or torch.Tensor on the GPU
image = camera.capture()
if image is None: # in case of timeout, keep trying
continue
# returns a np.ndarray or torch.Tensor with vla.dof elements
# for OpenVLA, this is (Δx, Δy, Δz, Δroll, Δpitch, Δyaw, gripper)
actions = model.vla.predict_action(
image,
instruction="pick up the nearest object",
action_space="normalized",
return_tensors='np',
)
# send the actions to your robot controller or IK solver
...
VLA models are also supported in Agent Studio , which includes the simulator components as well.
Online Validation
Given the challenging task domain, dynamic feedback loops, and computational demands for sim/training/inference, using VLAs for language-guided dexterous manipulation involves a significant increase in complexity over baseline usage of LLMs and VLMs. To go from predicting logits at the token level to actions consistently correct enough over an extended series of frames to form useful behaviors, it's important to cross-check outputs and measure accuracy at each stage of the training/inference workflow to be able to identify the source of potential regressions when they occur.
Unlike typical applications in supervised learning, the metrics for end-task completion and success aren't measured from static pre-recorded datasets that don't account for the temporal domain and feedback from physical interactions along with compounding errors - they require online validation, either in simulation or real-world tests.
 Closing the Sim-to-Real Gap: Training Spot Quadruped Locomotion with NVIDIA Isaac Lab
Closing the Sim-to-Real Gap: Training Spot Quadruped Locomotion with NVIDIA Isaac Lab
During training the token classification accuracy is measured from the groundtruth action labels (i.e. how many action tokens were predicted exactly right), with the model optimizing to minimize this loss (as is normal for LLMs). Action accuracy in the continuous domain is also is also measured during training from the L1 error of the detokenized real-valued outputs. Continuous action accuracy trends slightly higher than token classification accuracy, as the later does not provide any reward for being closer to the desired result. In practice, these should be >95% accurate at this level for completing tasks successfully in similar environments. To achieve that high degree of accuracy, it seems intentional in the work and related research to overfit the model by training it for many epochs (upwards of 30 epochs on the same 900K episodes for OpenVLA). Transformers are known to recall specific knowledge from few training examples, and are sensitive to overfitting and forgetting previously learned information. As such, LLMs are normally only trained for a few epochs at most to preserved their zero-shot capabilities and ability to generatize to out-of-distribution inputs. During the fine-tuning part of this project, we characterize the impacts on model accuracy and task success from the number of distinct training episodes versus the number of epochs over repeated data.
The actual task success rate doesn't get measured until the inference stage, when it is either connected to a simulator or physically tested in a series of time-consuming trials under similar conditions. We integrated MimicGen directly with the OpenVLA training scripts for an endless source of unseen data, but encountered gradient instabilities after the model had received a significant number of episodes.
Simulation with MimicGen
MimicGen creates randomized episodes from as few as 10 teleoperated examples by utilizing scene graph information and task/subtask metadata about which objects in the environment are targets of the current subtask, in order to interpolate the original teloperated trajectories into their new random locations and poses. This generates large amounts of unique training data to improve robustness, without needing large amounts of human effort for the robot learning new skills and behaviors.
MimicGen is built on the Robomimic and Robosuite simulators and are able to run onboard Jetson headlessly alongside the VLA, simplifying the setup for reproducibility. The RoboCasa project is built on MimicGen and being integrated with NVIDIA Omniverse and OSMO , and in future work we'd use Isaac Lab for scalability, more accurate physics, and photorealistic rendering.
MimicGen includes 12 tasks like block stacking, pick and place, assembly, and kitchen scenarios. And each type of task has variants increasing in difficulty as learning progresses, which would be interesting to compare curated approaches to the purely random sequencing that OpenVLA uses with Open X-Embodiment. In this phase of the tutorial, we focus on the block stacking task to understand the training requirements and runtime performance needed to master a new task with success rates of >75-80%, similar to the paper . This will help inform scaling to multiple behaviors and more complex scenarios that vary significantly from in-distribution examples like the MimicGen environments (as evidenced by the original OpenVLA weights scoring zero successes in them).
Data Generation
We built MimicGen containers for Jetson from a
fork
of the code with some patches for aarch64+igpu along with enhancements like generation of natural language labels with random variations for the relevant tasks, along with additional domain randomization for the colors/materials of objects (these environments were added as
Stack_D2
,
Stack_D3
, and
Stack_D4
). For training OpenVLA, the images and labels are saved to disk, whereas later inference is done with online simulation to measure the task success rate. To that effect we integrated MimicGen with
Agent Studio
for interactively testing the models and quickly dropping in components like ASR for verbally commanding the robot.
Online Training
There's initial support for direct integration of MimicGen in this fork of OpenVLA for live simulation and validation during training and endless episodes without repeating epochs. The models experienced spiking gradients later into LoRA's, and should try again with lower learning rates or by similarly integrating MimicGen into their full fine-tuning script using FDSP for increasing the batch size on dGPU.
This command will generate the specified number of training episodes, saved in Robomimic HDF5 format . We provide the rendered datasets for these on HuggingFace Hub with 1000 and 2500 episodes. OpenVLA suggests only needing 10-150 episodes for fine-tuning and data-efficient adaptation, which perhaps performs similarly in comparable spaces, but we ultimately found insufficient for the MimicGen environments.
jetson-containers run $(autotag nano_llm) \
python3 -m mimicgen.generate \
--tasks Stack_D4 \
--episodes 100 \
--output /data/datasets/mimicgen \
--cameras agentview \
--camera-width 224 \
--camera-height 224
The HDF5 dataset will be saved to
/data/datasets/mimicgen/demo_src_stack_task_D4/demo.hdf5
(which is in a mounted volume under your
jetson-containers/data
directory outside of the container), along with a video of sample episodes that were rendered:
This video is actually of Stack_D2 to avoid subjecting everyone to flickering colors. Stack_D4 is used for training and generates blocks with random colors and positions each frame, along with language labels augmented through the random combination of various nouns, adjectives, and verbs that form the instruction (
Stack the red block on the green block
,
Put the little cube on top
). Stack_D3 randomizes colors/positions each frame, and instructions each episode. Stack_D2 does them all per-episode (which is typically used at runtime). Since OpenVLA uses a single frame at a time with no temporal aspect during training, applying domain randomization per-frame as opposed to per-episode is feasible provides more variance in the dataset. The block-stacking episodes typically come out to be around ~110 frames each, and take around 10-15 seconds to generate per episode on Jetson AGX Orin with per-frame domain randomization, and 5 seconds per episode without domain randomization.
The agentview camera looks onward from the front of the scene towards the robot. There are others available like sideview and eye_in_hand (wrist view) - we tried using the onboard wrist camera, but found the model would too easily veer off track and get 'lost' offscreen. It may be possible for wrist-only to work should the dataset add examples of the robot recovering and returning to a wider vantage point. Other VIT-based embodied models like Octo and CrossFormer use both cameras, and is a future experiment with VLA's based on multi-image VLM's like VILA .
RLDS Conversion
OpenVLA uses datasets in RLDS format (which is based on TFDS ), so we provide a converter from HDF5. This extra step can also be time-consuming for a large number of epiodes, like those used here. This is one of the reasons we desire to run MimicGen online with training and performed the initial integration directly with OpenVLA. Unless you are generating different data, you can skip this and use the MimicGen datasets that we uploaded here in RLDS format.
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.datasets \
--dataset /data/datasets/mimicgen/demo_src_stack_task_D4/demo.hdf5 \
--dataset-type mimicgen \
--convert rlds \
--remap-keys agentview:image \
--output /data/datasets/mimicgen/rlds/stack_d4_ep2500
This will create a set of tfrecord files under the output directory that are able to be loaded by the OpenVLA training scripts.
Fine Tuning
A primary objective of this project is to characterize the training needed to adapt the model to different robots and tasks. Our development primarily consisted of running test LoRA's onboard Jetson AGX Orin 64GB and debugging issues locally, and when the results were encouraging to perform a full fine-tuning with FDSP on multiple A100/H100's from spot instance providers like Brev.dev , Vast.ai , and RunPod . Full fine-tuning on 2x Jetson AGX Orin's was attempted with FDSP, but ran out of memory with all settings that we tried. We provide the test models we trained on HuggingFace for others to try in the inference + sim setup below. Below are the training GPU configurations that were used, along with their batch sizes that maximized memory usage:
| Batch Size | FPS | $/hr | |
|---|---|---|---|
| Jetson AGX Orin 64GB | 8 (LoRA) | 1.57 | - |
| 2x A100 SMX4 80GB | 48 | 13.07 | ~$1.50 |
| 8x H100 NVL 94GB | 256 | 92.4 | ~$25 |
The rental fees are ballpark averages over the spot instances available with these GPUs at the time of writing, and becomes quite reasonable when used alongside a Jetson repurposed for training daily test LoRA's on a reduced amount of data. Training until convergence on Jetson and 2xA100 took roughly 24-36 hours depending on the amount of data and number of epochs. We kept to <5 epochs for the full fine-tunes in an attempt to prevent the afformentioned overfitting, instead opting to increase the number of episodes.
Below we provide the steps to run the OpenVLA LoRA training on Jetson, and for the dGPU systems refer to Fully Fine-Tuning OpenVLA . Typically you will launch a spot instance with your provider of choice in a CUDA or PyTorch container, then install the OpenVLA repo and its dependencies with pip, and download your dataset to the system before launching the command (or create a bundled container with it all included to save time). Here's the WandB Dashboard from the full fine-tuning runs that you can inspect, comparing a fewer number of episodes for more epochs, versus a larger number of episodes trained for fewer epochs:
On-Device LoRA
The OpenVLA repo provides working training scripts for LoRA/qLoRA and multi-node multi-GPU full fine-tunes using PyTorch FDSP. It was not difficult to go in a make changes and enhancements, some of which we have done for our purposes of on-device training in this fork . Overall we found the process to be more similar than not to training other vision DNNs, just with larger datasets and rigorous validation required of the data pipeline that all the coordinate spaces and transformations matched up at every step of the sim→training→inference workflow.
We built an OpenVLA container for JetPack that runs the LoRA training, which you can find the specific documentation about from the OpenVLA readme (it's also recommended to read their paper which includes many insights into the training process).
jetson-containers run $(autotag openvla) \
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path openvla/openvla-7b \
--data_root_dir /data/datasets/mimicgen/rlds \
--dataset_name stack_d4_ep2500 \
--run_root_dir /data/models/openvla \
--lora_rank 32 \
--batch_size 8 \
--grad_accumulation_steps 2 \
--learning_rate 5e-4 \
--image_aug False \
--save_steps 250 \
--epochs 5
This will start a TensorBoard server on port 6006 to monitor the training progress. Typically you would set the script running for more epochs than you intend to actually run, so that you can instead stop when the model converges (typically occurring with a loss below 0.5 and token accuracy >95%). This script was adapted so that if you interrupt training by pressing
Ctrl+D
from the terminal, it will gracefully stop early and still merge the LoRA weights before exiting. If training is terminated otherwise, we added a
merge.py
script that you should run afterwards get the model ready for inference.
Validation
Now that we have trained our test model (or you can download one from
here
), let's re-validate it again like we did
above
on the original OpenVLA model, but this time on unseen data from MimicGen with a different random seed (
dusty-nv/mimicgen-stack_d4-ep100
). These commands will download and run the fully fine-tuned checkpoint (on 2500 episodes for 4 epochs) that we released to (
dusty-nv/openvla-7b-mimicgen
. If you trained your own model, you can substitute the local path to the HF checkpoint.
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.vla --api mlc \
--model dusty-nv/openvla-7b-mimicgen \
--quantization q4f16_ft \
--dataset dusty-nv/bridge_orig_ep100 \
--dataset-type rlds \
--max-episodes 10 \
--save-stats /data/benchmarks/openvla_mimicgen_int4.json
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.vla --api mlc \
--model dusty-nv/openvla-7b-mimicgen \
--quantization q8f16_ft \
--dataset dusty-nv/bridge_orig_ep100 \
--dataset-type rlds \
--max-episodes 10 \
--save-stats /data/benchmarks/openvla_mimicgen_fp8.json
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.vision.vla --api hf \
--model dusty-nv/openvla-7b-mimicgen \
--dataset dusty-nv/bridge_orig_ep100 \
--dataset-type rlds \
--max-episodes 10 \
--save-stats /data/benchmarks/openvla_mimicgen_fp16.json
The results from this are collated in the next section along with the end-task success rates. Time to see it in action!
Inference + Simulation
To measure how well our model actually performs at completing the task, we spin up a MimicGen environment in Agent Studio that's connected to the VLA model. It counts the number of successful episodes by checking the reward issued by the sim, which is not used by the model but signals when the task was completed. We use a horizon of 200 frames for evaluation, after which it is deemed to be a failure.
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.studio --load OpenVLA-MimicGen-INT4
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.studio --load OpenVLA-MimicGen-FP8
jetson-containers run $(autotag nano_llm) \
python3 -m nano_llm.studio --load OpenVLA-MimicGen-FP16
To start the benchmarking, connect the output of the
AutoPrompt
node to the
OpenVLA
node. On its own it will run forever - we did it for 100 episodes each, which can take several hours since the sim operates in lock step with the model (future experiments will train on actions accumulated from multiple timesteps and also reduce the model size to improve performance).
| Quantization | Train Accuracy | Val Accuracy | Task Success | Avg Frames | Latency | FPS |
|---|---|---|---|---|---|---|
| FP16 | 96.5% | 85.4% | 86% | 132 | 827 ms | 1.20 |
| FP8 | 96.2% | 85.1% | 85% | 131 | 467 ms | 2.14 |
| INT4 | 95.4% | 84.4% | 84% | 138 | 335 ms | 2.98 |
This is using the model fine-tuned on 2500 episodes for 4 epochs, and although the task may have been simple, is evidence of achieving the sought-after success rates of ~85%. Quantization has a negligible ~1% impact while scaling performance almost linearly. The average number of frames is how long it took the robot to complete the task, which efficiency is another important end-metric to evalulate models by (consider the source teleop episodes were ~110 frames long, and we realized after that these averages include failed episodes during evaluation). The training dataset
dusty-nv/bridge_orig_ep2500
was used to measure the action Train Accuracy, while the previously unused and distinct
dusty-nv/bridge_orig_ep100
was used for Validation Accuracy.
Episodes vs Epochs
Upon measuring the success rates of the other fine-tuned models that were trained on fewer episodes for more epochs, we can see the impact of increasing the size of the dataset:
| Episodes | Epochs | Frames | Task Success | Avg Frames |
|---|---|---|---|---|
| 500 | 10 | 550K | 23% | 186 |
| 1000 | 6 | 660K | 48% | 165 |
| 2500 | 4 | 1.1M | 84% | 138 |
That isn't to say that the 2500-episode model still isn't overfit - it is after learning to always stack the smallr block and essentially ignore the instructions. More task diversity in the training is required, which we can do now that we have the workflow. And we want to branch out into real-world domains instead of test environments in simulation to prove model viability. The amount of variance and data required to achieve generalist models in the challenging problem space of manipulation does raise interesting questions about purely random task learning versus more guided and curated approaches that ramp up in complexity as training progresses.
Future Research
Embodied agents are an exciting emerging area at the forefront of robotics and physical AI, with many promising avenues to investigate further. Follow-up publications to OpenVLA include Embodied-CoT and CrossFormer , along with others sure to be in development. In addition to proceeding to physical testing, these areas of interest we'll experiment with as research progresses:
- Smaller LLM with higher-resolution vision encoder(s)
- Multiple image inputs - multiple cameras and/or timesteps
- Action states from previous frame(s) as input
- Training on consecutive actions for larger timesteps
- Similar test model for UGV's in sim
- Using Isaac Lab and Robocasa
- sim2real deployment with ROS2
- Trade-offs of VLA vs VIT-based approaches